Taking care of research data is an essential part of good scientific practice. Already when drafting a data management plan, a researcher needs to consider what happens to the data after the research is concluded and findings possibly published. What data should be retained and where to deposit it? Good data management is also research organisation’s responsibility. How does the organisation keep track on their datasets and help researchers to manage the dataset lifecycle? What data should be for example identified as especially valuable and prepared for digital preservation?
Funders, such as the Academy of Finland, and many publishers might require making the data available. Data need to be opened responsibly: “As open as possible, as closed as necessary”. If the data itself can not be made available, for example sensitive data, one can make the data more open by publishing descriptive information related to findability.
Making data available does require work but is also rewarding. Opening data, or descriptive information, makes the research more visible which can lead to new co-operation. Opening the data also increases the transparency and trustworthiness of the research. Therefore open data brings merit both to the researcher and research organisation. Producing data is often expensive and requires a lot of work. Publishing data means that you are able to reuse it later on. And as others make their data available as well, you will be able to use data collected by other in our research.
There are steps that need to be taken before the data can be made available – they have to be logically and systematically organized, documented, and there needs to be sufficient metadata. The Fairdata services are made to ease these tasks by providing services and tools designed for storing and sharing data, publishing and finding datasets and for the digital preservation of research data. The Fairdata services can be used by a researcher, or for example by organization data support who stores and publishes data on behalf of the researchers. Let’s take a closer look at how this is done.
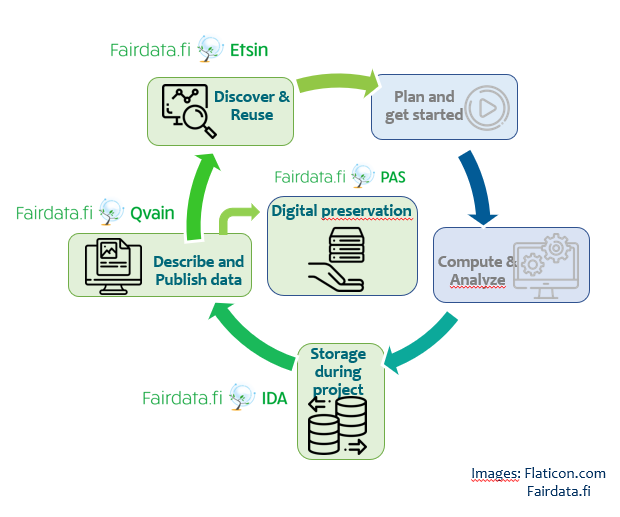
Storing data: Published research data needs to be stored in an immutable state and its integrity needs to be looked after. You may also need to use a shared storage space before you the research data is ready for publishing. This is provided by Fairdata IDA.
Publishing datasets: Regardless where the actual data is stored, research data needs descriptive metadata. Quality metadata helps everyone else understand what the data is about and how it can be used. Datasets may also need for example access control. Sometimes only the metadata can be published. You can describe datasets and control their access with Fairdata Qvain.
Finding datasets: Once a dataset has been published, it needs to be findable. Fairdata Etsin lists datasets from multiple sources and enables searching them. The more detailed the dataset metadata is, the easier it is for others to find the dataset. A dataset published with Fairdata Qvain gets a persistent identifier which always points to the same version of the dataset in Fairdata Etsin. It’s essential to use the persistent identifier when citing the dataset.
Digital preservation: The research organization can decide if a dataset is especially valuable and needs to be digitally preserved for the future, meaning tens and even hundreds of years. This is provided by the Digital Preservation Service for Research Data.
Are the Fairdata services suitable for our datasets?
What type of service is suitable for certain data depends on factors such as the requirements of the funding body or the research organisation, and common practice in the academic field. There are institutional repositories, international general data repositories (e.g. EUDAT), subject or domain specific data archives (e.g. Dryad, Genbank, Tietoarkisto), data type specific services (such as Github for software), and national general repositories (Fairdata). Data journals are a new format of peer-reviewed academic publications that specialize in publishing research data in the form of data article (see for example Brain and Behavior, or Geoscience Data Journal).
IDA and Etsin are listed in the Registry of Research Data Repositories, a database of trusted research data services, and both are also well known and recognized as trusted for example in the Academy of Finland grant application process. If you are considering using Fairdata services for data management, consider the criteria mentioned above. Note that data protection issues also affect the selection of storage service: IDA is not suitable for the storage of sensitive personal data.
When considering the options take into account these Fairdata service benefits:
- We accept datasets from all disciplines.
- The services are free-of-charge for users in Finnish higher education institutions and state research institutes and for their collaborators.
- Fairdata services support creating interoperable quality metadata and mint PIDs (DOI/URN) to published datasets, so that the datasets follow the FAIR principles.
- We support publishing large datasets as there is no hard size limit in storing nor publishing the data.
- Dataset can be marked as a ”growing dataset” which means that you can add more data to it after it has been published. Whoever then finds and sees the dataset in Etsin will be informed that this dataset is not static but may grow later on. This makes sure that any citations to the growing dataset are clear and valid.
- Once the data have been stored and described with the Fairdata services, it is technically simple to transfer the dataset into the Digital Preservation Service to ensure that the dataset remains accessible and usable for tens or even hundreds of years.
- In addition to Fairdata Etsin, the published datasets are also visible in national Research.fi portal. In Research.fi portal the dataset will be linked to other research information, which further increases the visibility and findability of the dataset.
- We are constantly developing the services, for example to support the research organisation’s ability to manage stored datasets and their metadata.
What do the Fairdata services look like?
All of the Fairdata services the researchers use have graphical user interfaces. The services are used with a web browser, for example with Chrome or Firefox. The services don’t require installing any software. Using these services does not require much technical knowledge and Fairdata.fi website has detailed user guides for IDA and Qvain, that explain how to use the services.
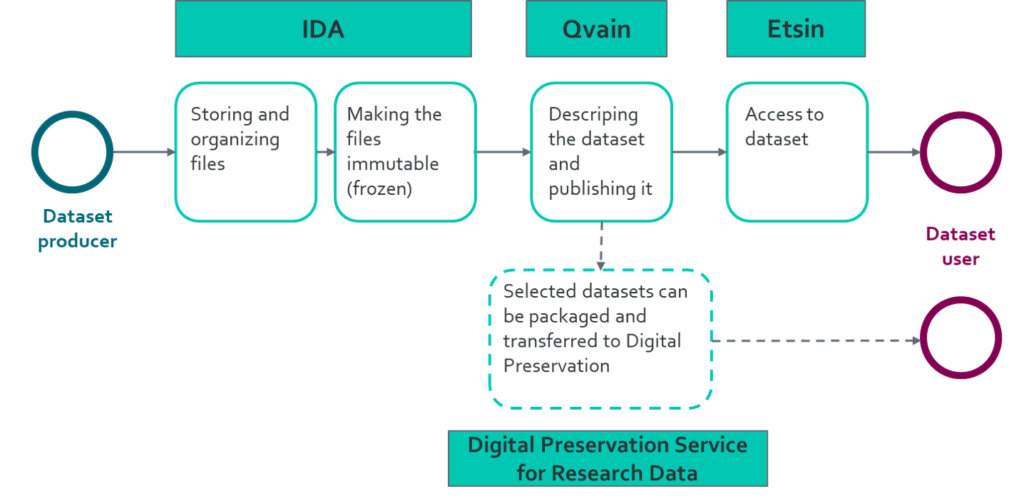
Research organisations propose datasets for Digital Preservation Service for Research Data through a management interface. The researcher can save and describe their datasets in Fairdata IDA and Qvain services and after this the research organisation representatives transfer the finished dataset for preservation.
IDA
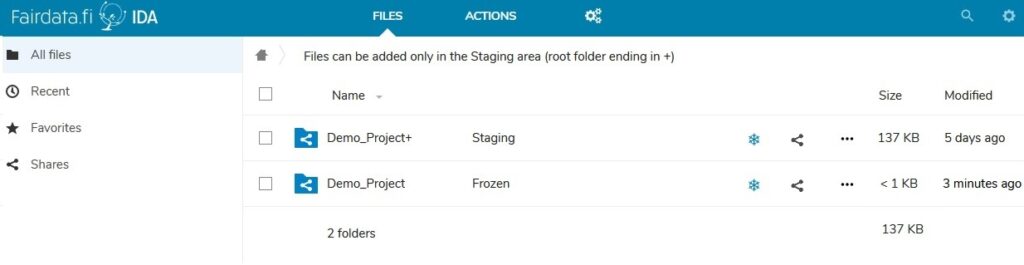
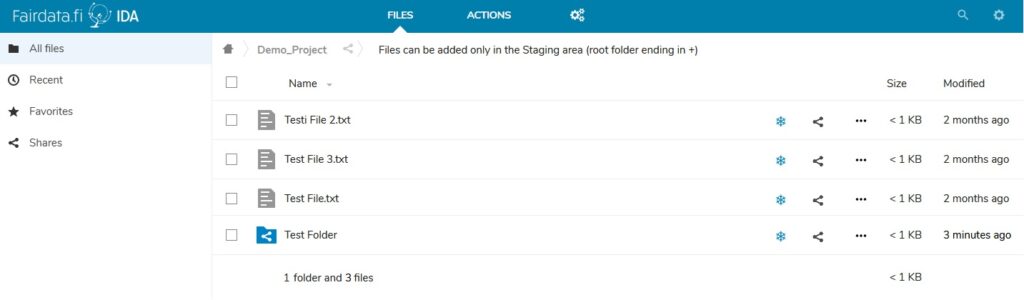
The above screenshots are taken from the Fairdata IDA service after logging in. In this service you can store files, reorganize them into a final folder structure inside a project specific storage area and then finally freeze them. After the files are frozen, they are in an immutable read-only state and they can be included to datasets with the Fairdata Qvain tool. The user interface is very simple and quick to learn.
IDA has command line tools available for heavy users who store big amounts of data or who for example want to transfer data to IDA from CSC’s supercomputers.
Qvain
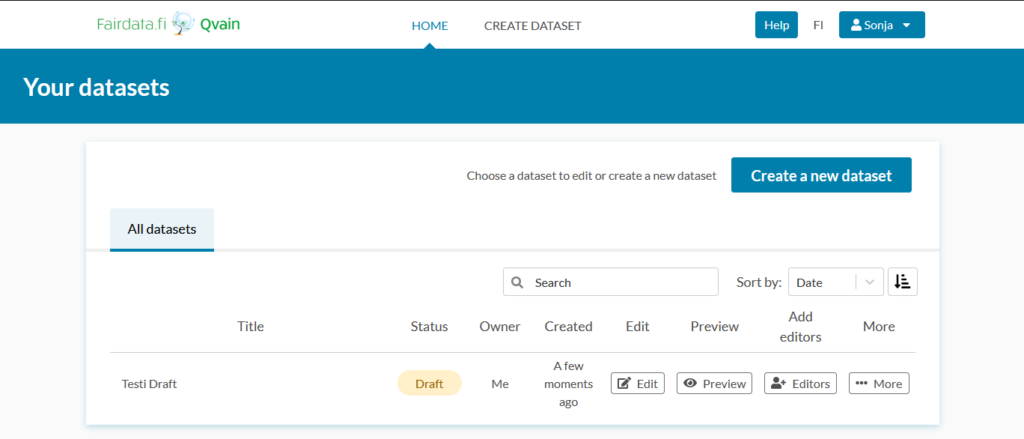
Fairdata Qvain is the Research Dataset Description Tool. The first screenshot above is the page that is visible to you when you first log in. After you have described datasets, they are listed here. Here you can also share dataset editing rights to other users, so that you can co-edit dataset descriptions.
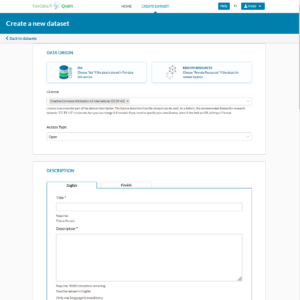
The second screenshot is the form, where you describe the dataset. Here you fill in the information about the dataset, such as its Title, Creators, License and Access type. Here you also either include frozen files from IDA to the dataset, or tell that the dataset files are located somewhere else, outside the Fairdata services. All you need to do is fill in the fields, and then save and finally publish the dataset.
Etsin
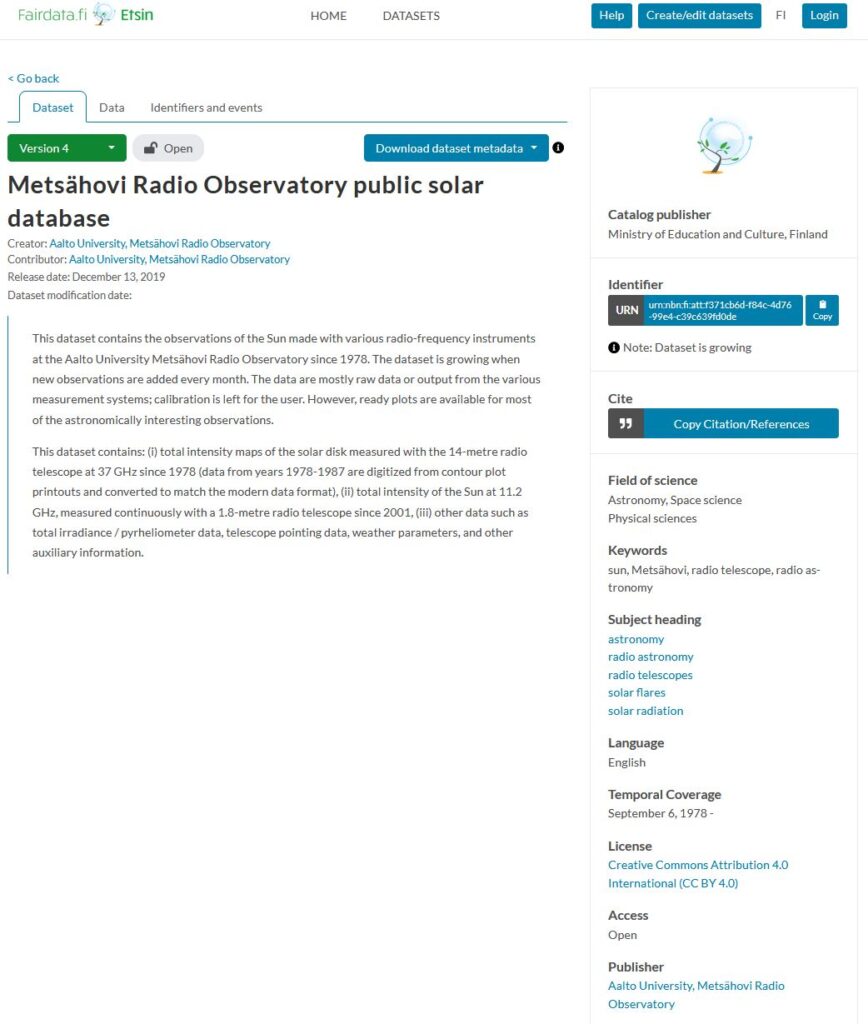
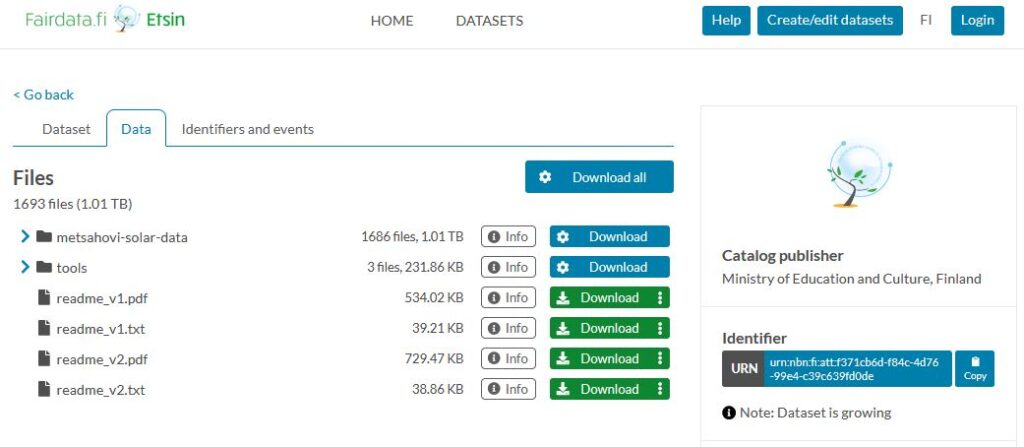
Etsin is the service that shows the published datasets. Each dataset has its own landing page where all the metadata can be seen. The dataset’s persistent identifier resolves to this page. The dataset landing page has its own tab for downloading the data, if the data is made openly accessible.
In Etsin you can search, view and download datasets created by others. You can choose to view for example only openly accessible datasets, or datasets from a certain organisation.
How much are the Fairdata services used?
The Fairdata services have been in active use for several years and the oldest data in Fairdata IDA was stored in 2012. Now about ten years later we have over 1 petabyte of data stored in IDA and over 4000 published datasets in Etsin! Currently Fairdata IDA stores data from nearly 400 projects.
8 Finnish higher education institutions and state research institutes have started to utilize the Digital Preservation Service for Research Data. The other Fairdata services have users from tens of Finnish higher education institutions and state research institutes.

