Publishing research data with Qvain Tool: Qvain introduction video
CONTENT
GETTING STARTED
The research dataset description tool Qvain can be found at qvain.fairdata.fi. Qvain can also be accessed at etsin.fairdata.fi via the “Create/edit datasets” button in the page’s upper corner.
You need an active CSC customer account in order to use Qvain (instructions can be found here).
Once you have an active CSC customer account, you can log into the service at qvain.fairdata.fi by using your Haka, Virtu or your personal CSC account.
IDA, Qvain and Etsin use a common single sign-on/sign-off (SSO) service. This means that you will log into all of these Fairdata services when logging in once through IDA, Qvain or Etsin. Similarly, logging out will log you out of all of the services.
To log into Qvain, click the “Login” button in the page’s upper right corner. Choose “CSC Login” or “Haka Login” and follow the instructions.
Please note that your personal CSC customer account can be managed through MyCSC ( e.g. creating an account or changing the CSC account’s password).
Note! To improve security, Fairdata Services will require multi-factor authentication (MFA). MFA will be taken into use during the Spring 2026 (exact date will be informed later). MFA is already required for e.g. the MyCSC web portal. Detailed documentation can be found here: https://docs.csc.fi/accounts/mfa/
FRONT PAGE
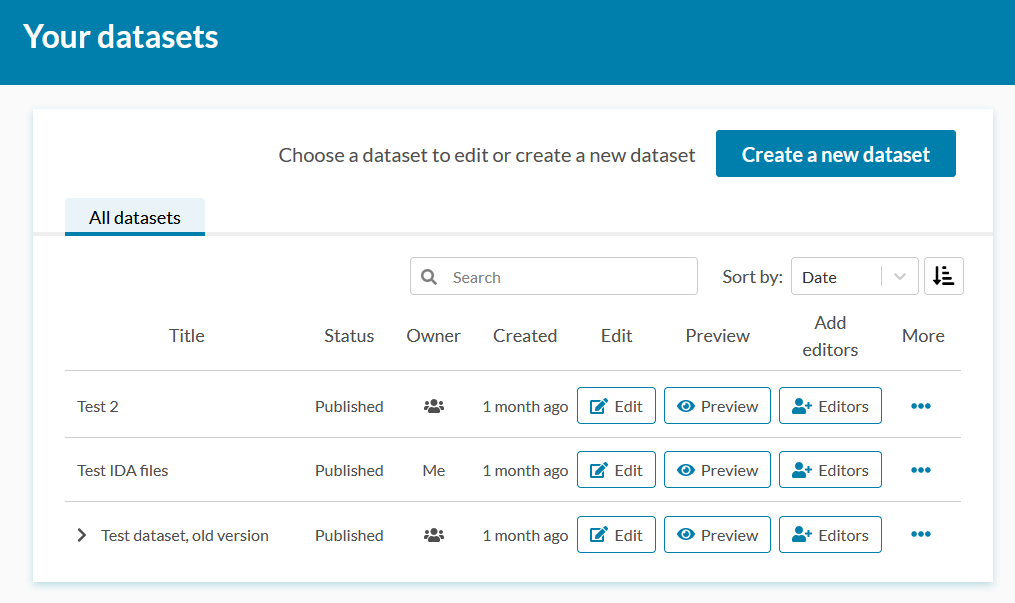
Qvain’s front page lists all the datasets you have defined in the service. From the front page, you can either create a new dataset or edit an existing one.
Creating a new dataset
You can create a new dataset by clicking the “Create new dataset” button or or by clicking “Create dataset” at the top of the page.
Dataset list
In the dataset list, you will find the following information regarding each dataset: the dataset’s title, status, owner (you / someone else), when the dataset was created as well as the actions available for each dataset.
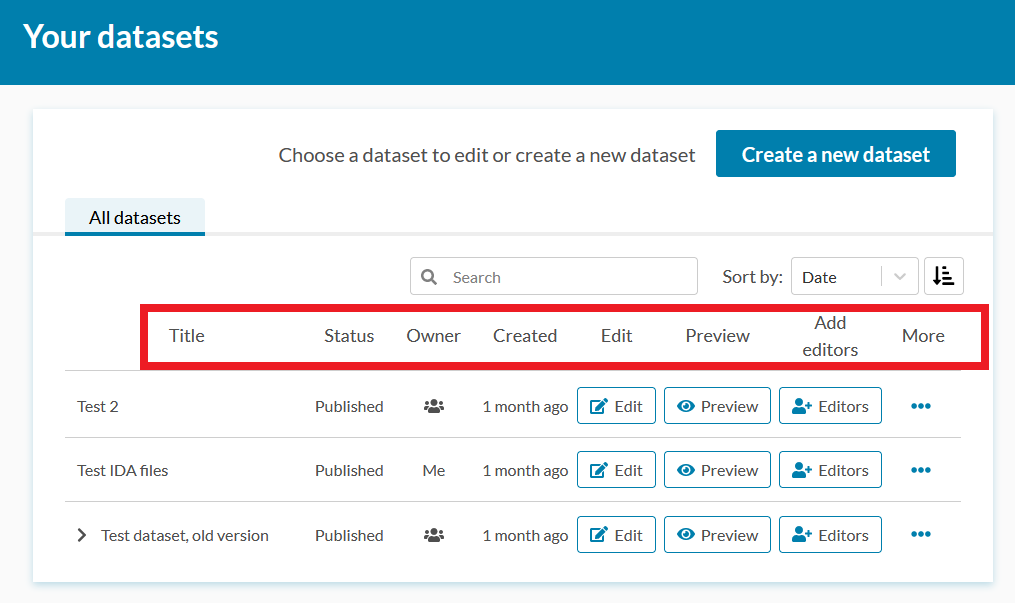
You can filter the datasets by name using the search box above the dataset list.
The status of a dataset is either “Published” or “Draft”. Published datasets are displayed publicly to everyone in Etsin (even when access to the data included in a dataset is restricted, the metadata describing a published dataset is always public). Datasets with a “Draft” status are only visible to the person who created the dataset when they are logged in to Etsin.
If multiple versions of the dataset have been created, you can view the older versions by clicking the “>” in front of the latest version of the dataset. All versions of a dataset can be edited.
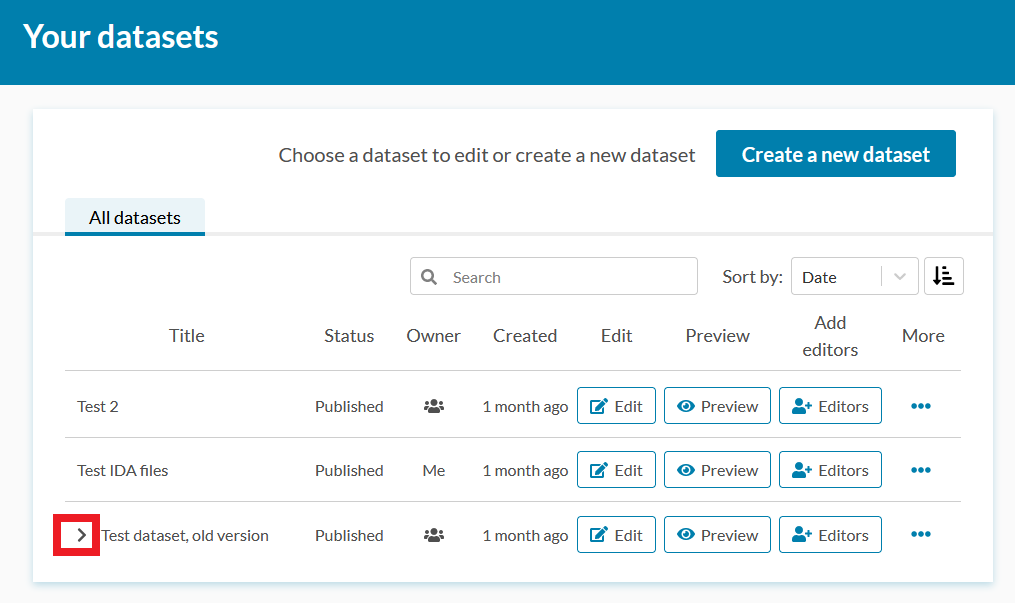
When you view a dataset through Etsin’s search, the latest version of the dataset is shown by default. You can also switch to view older versions of the dataset.
In the “Actions” section on the front page’s dataset list, you can
- Click “Edit” to edit a published or draft dataset.
- See what the dataset looks like in Etsin by clicking “View in Etsin”.
- Share editing rights with other users by clicking “Editors”.
- Use an existing dataset as a template to create a new dataset by clicking “Use as template” from the “More” drop-down menu. In this case, Qvain copies all the descriptive information from the selected dataset to the fields of the new dataset form. NB! Files attached to a dataset will not be copied to the new dataset’s form when using the “Use as template” activity.
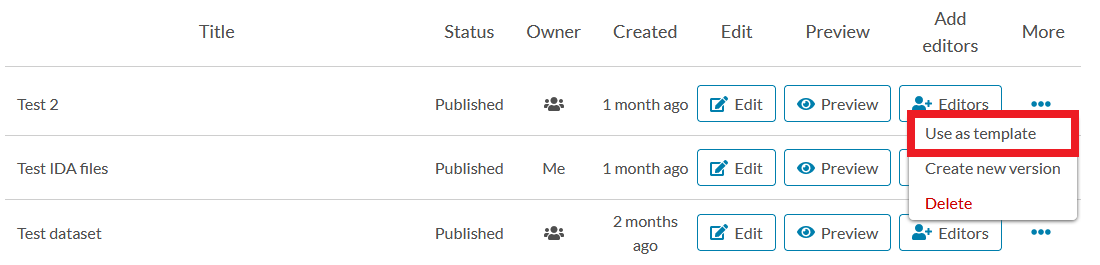
- Create a new version of the dataset by clicking the “Create new version” from the “More” drop-down menu. NB! When creating a new version of a dataset, old versions of the dataset will remain publicly visible in Etsin unless you delete them.
- Delete the dataset completely by clicking “Delete” from the “More” drop-down menu. If you delete a dataset that has a “Draft” status, the dataset will be permanently deleted. If, on the other hand, you delete a published dataset, it will be removed from Etsin’s search results and will no longer be visible in Qvain. The deleted material will, however, have a public description page in Etsin. You will be able to find this page in Etsin through the dataset’s permanent identifier.
DATASET DESCRIPTION
Fill in the Qvain form to describe your dataset.
More detailed list of Fields to describe your dataset can be found in Qvain Fields.
SAVE DATASET AS A DRAFT
You can save the information you have filled in on the form as a draft by clicking “Save” at the bottom of the page. When you save a dataset as a draft, you can preview it when logged in to Fairdata services in Etsin. Drafts are not visible to other users in Etsin.

PUBLISH DATASET
Click “Publish” at the bottom of the page to publish your dataset. After publication, your dataset will appear in Etsin (etsin.fairdata.fi) and you can edit it in Qvain if you wish. Note that only cumulative datasets’ files can be added after publication. In other cases, the files attached to the dataset cannot be changed except by creating a new version of the dataset.

Datasets’ metadata published by Qvain are automatically CC0 licenced. You can however define your own licence for the data itself, this is done in the “Licence” field in Qvain.
EDIT DATASET
You can edit the metadata of published or draft dataset (see versioning rules below).
To edit the dataset, click “Edit” next to the dataset you wish to edit in the dataset list on Qvain’s front page.
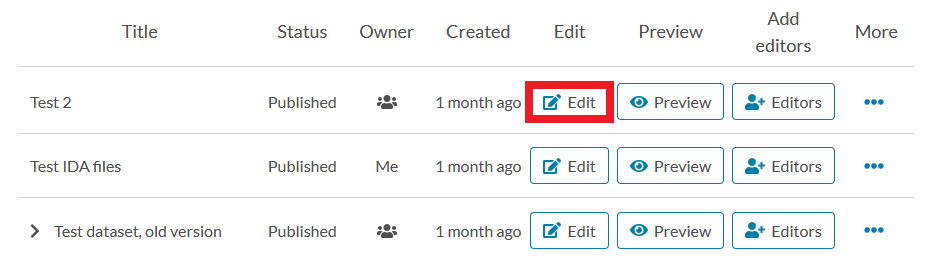
You can publish the changes made or save them as a draft. Changes to a dataset saved as a draft will be visible only to you when logged in to Etsin, whereas published changes appear in Etsin publicly to all users.
VERSIONING RULES
You can edit the metadata (e.g. actors, keyword, etc.) of published or draft dataset any time. Also editing Remote Data links (Remote Resources) can be done freely. After publishing, editing files linked via IDA service is subject to the following rules:
- Files of a published dataset cannot be deleted or modified. If you want to delete or modify files, you must first create a new version of the dataset (instructions below).
- You also cannot add files to a published dataset unless it has been set as a Cumulative dataset. New files can be freely added to a cumulative dataset but if not cumulative, files can only be added by creating a new version of the dataset.
- If the dataset has already been published as normal, non-cumulative dataset, it can only be changed to a cumulative one by first creating a new version of it.
- If IDA has been selected as the data source but the dataset has been published without files, it is possible to add files to it ONCE without needing to create a new version first.
- Adding files to the published metadata is automatically possible in Qvain if the published metadata does not yet contain any data AND IDA has been selected as the data source.
- After the dataset has been published with files, normal versioning rules apply — files can only be edited by creating a new version.
So, if you need to edit files after you have published the dataset:
- Ensure that the correct files are frozen in the IDA service.
- If you need to correct a file, make sure that you have frozen the corrected file version in IDA, or upload the desired new files to IDA and freeze them.
- Note that if you remove a file linked to a published dataset from the frozen area in IDA, that dataset version will be marked as deprecated in Etsin. Deprecated versions are still accessible via Etsin but data cannot be accessed any more. Alternatively, you can leave the old file in IDA and upload the corrected version with a different name (e.g., “version2”). More info about deprecation.
- (If needed) Create a new version of the dataset description in Qvain.
- The old version will remain visible in both Qvain and Etsin as it is.
- A link between the old and the new versions is created automatically, and Etsin will display the versions in a “version tree”.
- (A new version does not need to be created if you are only adding files (not removing any) AND the dataset is marked as a Cumulative dataset or has been published entirely without data.)
- Add the new/corrected files or remove incorrect files in the new version.
- Publish the new dataset version.
- Note that the version only truly exists and becomes visible in Etsin after it is published.
- You can now either keep the old version or delete it.
- Keep in mind that a deleted version can still be accessed in Etsin via its direct PID reference, but it will no longer be visible in Etsin Search nor in Qvain after deletion. If you want to explain why a dataset version was deleted, add that information to the version’s description before deleting it.
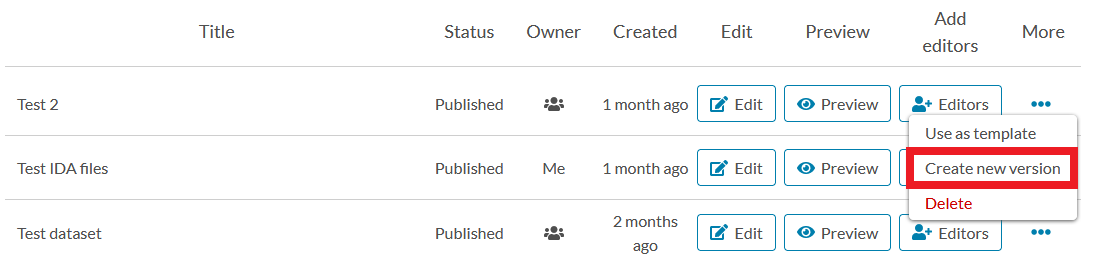
CREATING NEW VERSION
You can create a new version of a published dataset. A new version is needed if the dataset has data linked from IDA and you want to make changes to that data. Creating a new version ensures that the persistent identifier (PID) of the dataset always points to the same data and thus the versions of the dataset stay intact. To create a new version of a dataset, click “More” next to the dataset you wish to create a new version of in the dataset list on Qvain’s front page.
The new version of the dataset will not automatically replace the old version; instead, both versions will co-exist. After you publish the new version it’s visibly linked to the old version in Etsin and is assigned a new persistent identifier (PID). Only the latest version of the dataset is findable through Etsin Search. Older versions are not shown in search results but can still be accessed via their persistent identifiers or from the version history.
Over time, multiple versions of a dataset may be created, and it may become necessary to limit their visibility in Etsin.
You can remove old versions via the “More” menu in Qvain’s dataset list by selecting “Delete”. This will remove the version from the version history in Etsin, and you will no longer be able to access the removed version’s metadata via Qvain either. However, the removed version’s thombstone page will still be accessible through its direct PID reference even tough the data cannot be accessed any more.
EDITING RIGHTS
By default, if a dataset is an IDA dataset (data is stored in Fairdata IDA) all members of a CSC project that uses the IDA service have equal rights to edit the dataset: all project members can edit, publish and remove the dataset. They can also add and remove editing rights for other users.
If the data is not stored in IDA but is a “remote resource”, only the user who created the dataset has editing rights to it.
In the dataset list you can see all datasets which:
- You have created yourself (Owner: Me)
- You have editing rights to, either via project membership or by someone giving you individual editing rights (Owner:
 )
)
You have equal rights to edit all these datasets’ metadata, publish the changes, make new versions, add new editing rights and even delete the dataset. If the dataset is an IDA dataset and the data belongs to a CSC project you are not a member of, you can only see the included data but you cannot make any changes to the dataset.
The given editing rights are inherited to a new version of the dataset if a new version is created.
Using a dataset as a template for a new dataset does NOT copy the editing rights.
Adding and removing editing rights
In addition to the default editing rights, you can add editing rights for individual users. In the dataset list click the button “Editors” and a modal window will open.
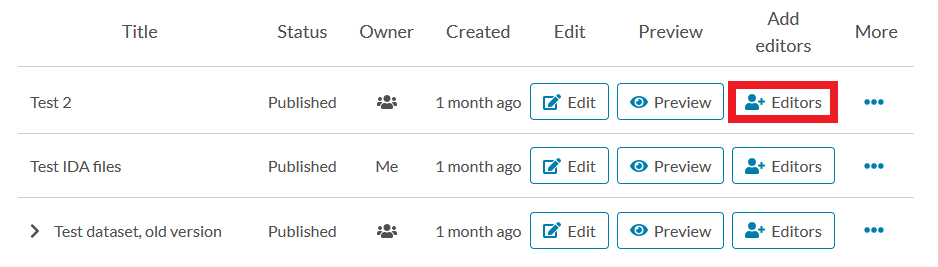
In the modal window you can either add a new user (Invite tab) or review/remove existing users (Members tab).
- Add a user (Invite tab) by starting to type his/her name: Qvain will auto-fill the user’s name once it finds a match. Click “Invite” to add editing rights for that user.
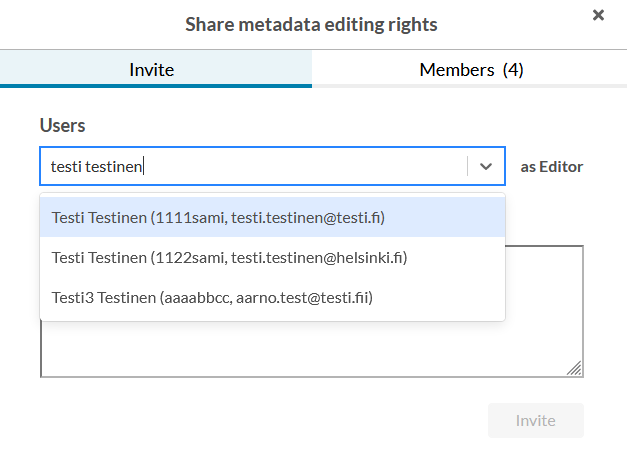
- Remove a user (Members tab) by selecting “Remove” from the Editor dropdown.
- You cannot remove the original creator of the dataset nor the users that have been added as editors via CSC-project membership.
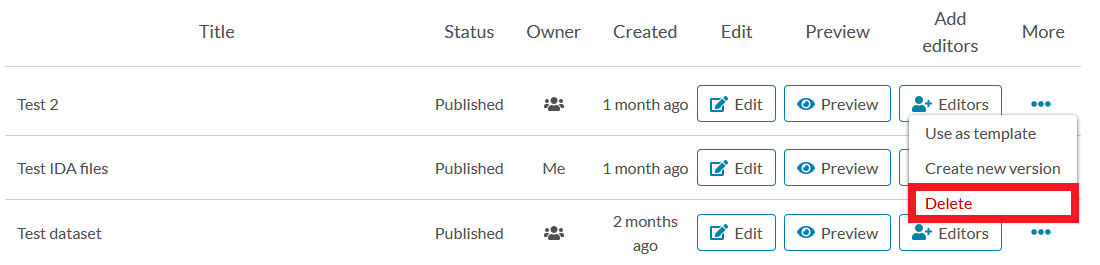
DELETING DATASET
You can delete a draft dataset and a published dataset. To delete a dataset, click “More” next to the dataset you wish to delete in the dataset list on Qvain’s front page.
If you have more than one version of a dataset, each version is deleted separately.
Deleting a published dataset will remove it from Qvain, and Etsin Search cannot find it anymore. The files included to the dataset can no longer be downloaded. Landing page for a published dataset will NOT be removed and it can still be accessed using its persistent identifier, but the landing page will have a notice saying “The dataset has been removed”.
Note: After deleting a dataset you can’t make changes to its metadata anymore, because it is removed from Qvain.